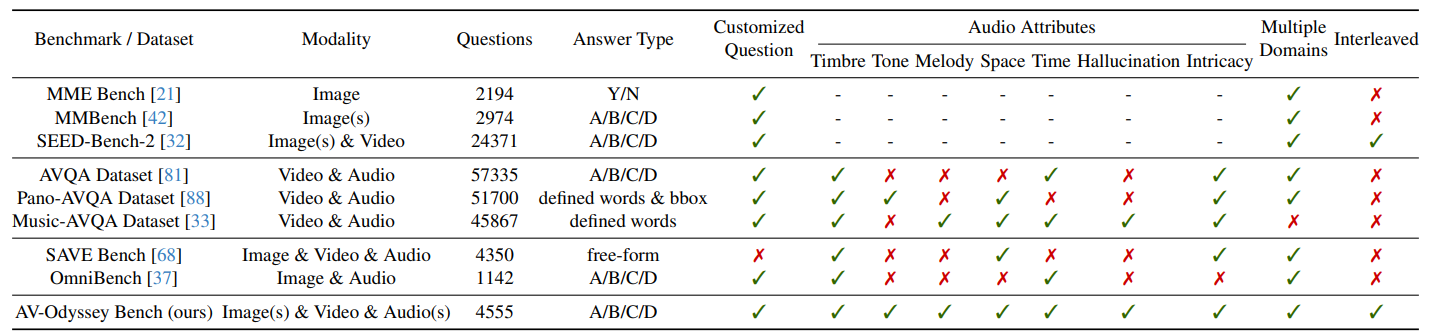
Evaluation results of various MLLMs in different parts of AV-Odyssey Bench.
By default, this leaderboard is sorted by results with Overall. To view other sorted results, please click on the corresponding cell.
| # | Model | LLM Params |
Date | Overall (%) | Timbre (%) | Tone (%) | Melody (%) | Space (%) | Time (%) | Hallucination (%) | Intricacy (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o audio caption
OpenAI |
- | 2024-11-10 | 34.5 | 38.6 | 31.8 | 33.6 | 32.5 | 27.5 | 25.0 | 26.1 | |
| GPT-4o visual caption
OpenAI |
- | 2024-11-10 | 32.3 | 37.4 | 28.6 | 32.3 | 27.5 | 25.5 | 23.0 | 28.9 | |
|
Gemini 1.5 Pro
|
- | 2024-11-10 | 30.8 | 30.8 | 31.4 | 31.3 | 37.5 | 27.7 | 20.5 | 33.0 | |
|
Gemini 1.5 Flash
|
- | 2024-11-10 | 27.8 | 27.2 | 25.0 | 28.8 | 30.0 | 25.3 | 28.5 | 31.2 | |
| OneLLM
MMLab |
7B | 2024-11-10 | 27.4 | 25.0 | 25.5 | 21.5 | 37.5 | 29.3 | 25.5 | 38.4 | |
| Unified-IO-2 XXL
Allenai |
7B | 2024-11-10 | 27.2 | 26.3 | 22.7 | 26.4 | 32.5 | 26.8 | 24.5 | 33.8 | |
|
Reka Core
Reka |
67B | 2024-11-10 | 26.9 | 26.7 | 27.7 | 26.4 | 22.5 | 26.5 | 24.0 | 34.3 | |
|
Gemini 1.5 Flash-8B
|
- | 2024-11-10 | 26.8 | 25.1 | 24.5 | 28.9 | 27.5 | 27.5 | 29.0 | 30.2 | |
| VideoLLaMA2
Alibaba |
7B | 2024-11-10 | 26.8 | 24.1 | 25.5 | 26.4 | 30.0 | 27.2 | 33.0 | 34.5 | |
| PandaGPT
Cantab & Tencent |
7B | 2024-11-10 | 26.7 | 23.5 | 23.2 | 27.6 | 45.0 | 23.8 | 28.0 | 23.9 | |
| VITA
Tencent |
8 x 7B | 2024-11-10 | 26.4 | 24.1 | 26.4 | 27.8 | 22.5 | 26.3 | 31.0 | 36.8 | |
| Unified-IO-2 XL
Allenai |
3B | 2024-11-10 | 26.3 | 24.3 | 23.2 | 27.8 | 22.5 | 25.3 | 31.5 | 34.8 | |
|
Reka Flash
Reka |
21B | 2024-11-10 | 26.3 | 25.5 | 24.1 | 27.2 | 30.0 | 27.5 | 31.5 | 24.1 | |
| Video-llama
Alibaba |
7B | 2024-11-10 | 26.1 | 25.5 | 22.3 | 24.4 | 30.0 | 26.2 | 25.0 | 30.7 | |
| AnyGPT
FDU |
7B | 2024-11-10 | 26.1 | 24.6 | 25.0 | 26.4 | 27.5 | 29.2 | 29.0 | 25.7 | |
| Unified-IO-2 L
Allenai |
1B | 2024-11-10 | 26.0 | 23.8 | 24.1 | 28.8 | 15.0 | 26.8 | 30.0 | 30.4 | |
| NExT-GPT
NUS |
7B | 2024-11-10 | 25.5 | 23.2 | 20.9 | 27.8 | 30.0 | 28.8 | 28.5 | 23.6 | |
|
Reka Edge
Reka |
7B | 2024-11-10 | 25.0 | 23.8 | 20.5 | 26.3 | 22.5 | 25.5 | 22.5 | 36.8 |
- indicates closed-source models with unknown parameters